▼ 2007/06/19(火) C#から形態素解析器のMeCabを呼び出してみた
| 環境 | |
|---|---|
| OS | Windows Vista |
| Visual Studio | 2005 + Vistaパッチ |
| MeCab | 0.96win |
| C# | 2.0 |
| MeCabSharp | 1.0.0.0 |
MeCabSharpのバージョンが上がってMeCab0.96に対応しました.
説明の一部は,そのままでは適用できない可能性があります.
2008/01/08追記:
MeCabのライセンスについての記述が間違っていたので修正しました.
GPL→GPL/LGPL/BSDのトリプルライセンス
thx: はてなブックマークのghostbass氏
2008/11/08追記:
MeCabSharpのサイトが移転していたのでURLを変更(移転先ページ)
■ MeCab
MeCabとは,京都大学情報学研究科と(補足: MeCab本体と一緒に配布されている形態素解析に用いるIPA辞書のライセンスについて「ipadicのライセンスの件 - mir the tritonn」)
このMeCabをC#から使う方法をメモします.
(形態素解析器については,メモを参照です.)
目次
このエントリは,MeCabをインストール済みと仮定して進みます.MeCabのインストールは,公式サイトからダウンロードしてインストーラの指示に従うだけなので特に注意すべき点はありません*3.
*1 : 公式サイトより
*2 : 研究者から見た特徴はまた違うことでしょう.詳しくはMeCabの公式サイトを参照のこと
*3 : Windows版の最新版をダウンロードしてくるようにしましょう……くらいです
■ あらまし
MeCabは,単体ではコマンドラインベースで動作するアプリケーション*4です.この機能を自作プログラムから使うには,標準入出力を経由してアプリケーション越しにデータをやり取りする方法もありますが,やはり関数などを直接コードから呼び出せた方が便利です.
そこで,MeCabの配布物にはlibmecab.dllというDLLファイルが付属しています.
しかし,これはC++で作成されているためにC++以外の言語から呼び出すには何らかのクッションが必要になります.
公式サイトには,
各種スクリプト言語バインディング(perl/ruby/python/java/C#)と書かれているんですが,なんとこの中でC#だけは配布されていません*5.
Swigというツールで自動的に生成するための定義ファイルは付属しているんですが,基本的にLinux*6が必要な上に私の技術力ではうまく生成できませんでした.
C++で作成されているので,きちんとインタフェースを定義してやればC#でラッパクラスを作れるはずなのですが,これも私の技術力では…….
そんなわけで,親切な方々がC#からlibmecab.dllを使うためのラッパクラスを配布して下さっています.
それが,MeCab.NETとMeCabSharpです.
どちらも違う作者の方が配布しているのですが,とても有り難いことです.
というわけで,ここでの「C#からMeCabを呼び出す」とは,「C#からlibmecab.dllの機能を使う」ということです.
■ MeCabSharpを使用可能にする
MeCab.dllとMeCabSharp.dll
2008/11/12現在、iconv.dllは必要無くなってるかも。未確認。確認したら書き直します配布ページからダウンロードリンクを辿って配布物をダウンロードしましょう.
ダウンロードしたアーカイブを展開してみるとわかりますが,中身はVisual Studio 2005のソリューションです.
配布ページの記述によると,その中で必要なファイルは
MeCab.dll (mecabラッパーDLL)の4種類であるそうです.
MeCabSharp.dll (mecabラッパーブリッジDLL)
libmecab.dll (mecabから持ってきてね)
iconv.dll (同上)
このうちMeCab.dllとMeCabSharp.dllは,展開したファイルの中に含まれています.
"/MeCab.dll"と"/bin/Release/MeCab.dll","/bin/Release/MeCabSharp.dll"です.
libmecab.dll
"MeCabをインストールしたフォルダ/bin/libmecab.dll"にあるファイルです.iconv.dll
iconv.dllは,配布ページの記述によると,mecabから持ってきてねとのことですが,実は2007/02/24にMeCabのWindows版が更新され,iconv.dllが同梱されなくなりました*7.
そこで,KaoriYa.netからiconv.dllを入手します.
次の二種類のDLLが配布されていて,どちらを使うべきか迷います.
- Libiconv DLL 1.10-20060516 for Windows
- Libiconv DLL 1.9.1 for Windows
気になる場合は両方試してみるといいと思います.
*7 : 実は,この関係で現在のMeCabSharpはMeCabの全機能を利用できないと思われます.MeCabSharpの完成後に追加された関数がありますので.しかし,簡単に使う分には問題無いはず.
■ MeCabSharpを使う
必要な4種類のファイルを取得すれば,準備は完了です.試しに使ってみましょう.
基本的にはVisual StudioでC#のプロジェクトを作成し,そこからMeCab.dllを参照するようにします.
残りの3種類のdllは,PATHが通っている場所に配置します*8.
簡単な手順の案内
1. C#のプロジェクトを作る
種類が色々ありますが,Windowsアプリケーションでも何でもいいです.2. MeCab.dllの配置
MeCab.dllをプロジェクトのフォルダのルートに配置します*9.プロジェクトのフォルダのルートは,プロジェクトを作ったフォルダ*10で,プロジェクト名.csprojがある所です.
追記:
どうもこれは嘘っぽいです.
必要なのは,次の二点.
- MeCabSharp.dllを参照に追加すること
- MeCab.dll,iconv.dll,libmecab.dllが参照できる位置に存在すること
MeCab.dllとiconv.dll,libmecab.dllは,例えば最初からPATHが通っているWINDOWS/system32に入れるとか,作成中プロジェクトの/bin/Debugに入れるとかするのが良さそうです.
他の方法が無いか試してみましたが良くわかりませんでした.
オススメは,開発に使うようなdllをまとめて置いておくようなフォルダを作ってそこにPATHを通し,MeCab.dll,iconv.dll,libmecab.dllをそこに入れておくことです.
配布時には実行ファイルと一緒に配布すればOK.
3. 参照を追加する
やり方は色々ありますが,【ソリューションエクスプローラ→参照設定→右クリック→参照の追加】が一番簡単だと思います.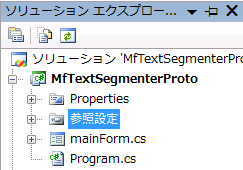
図 ソリューションエクスプローラと参照設定
この方法で,参照の追加ダイアログが表示されます.
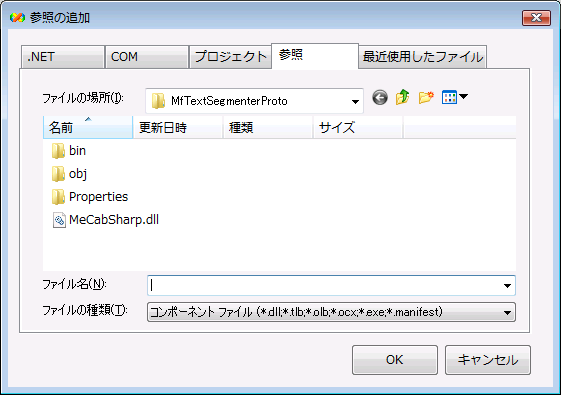
図 参照の追加ダイアログ
参照の追加ダイアログが開いたら,参照タブを選択して手順1で配置したMeCabSharp.dllを選択し,OKをクリックして下さい.
ソリューションエクスプローラの参照設定ツリー下にMeCabSharpがあらわれれば成功です.
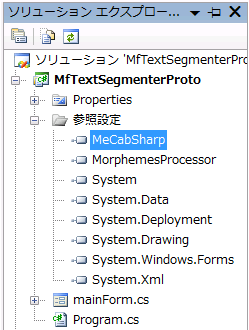
図 参照追加後の参照設定
これで準備は完了です.
サンプルコード
サンプルといっても凄く簡単です
MeCab.Tagger mecab = new MeCab.Tagger();
string result = mecab.parse("形態素解析器MeCabを使うテストです");
これだけで形態素解析結果と同じ文字列を取得できます.MeCabに引数を渡したい場合は,Taggerのコンストラクタで指定します.
ちなみに,上の文字列を解析した結果は,次のようになります.
形態素 名詞,一般,*,*,*,*,形態素,ケイタイソ,ケイタイソ最初の見出し語と品詞名の間はタブで,改行コードはLFです.
解析 名詞,サ変接続,*,*,*,*,解析,カイセキ,カイセキ
器 名詞,接尾,一般,*,*,*,器,キ,キ
MeCab 名詞,一般,*,*,*,*,*
を 助詞,格助詞,一般,*,*,*,を,ヲ,ヲ
使う 動詞,自立,*,*,五段・ワ行促音便,基本形,使う,ツカウ,ツカウ
テスト 名詞,サ変接続,*,*,*,*,テスト,テスト,テスト
です 助動詞,*,*,*,特殊・デス,基本形,です,デス,デス
EOS
後は普通にCSV形式なので煮るなり焼くなり.
*8 : 余談ですが,私はsystem32などに入れるよりも自分用のdllフォルダを作ってそこにパスを通す方が好きです.
*9 : 必須じゃないかも
*10 : ソリューションでは無いので注意.ソリューションのフォルダの直下にプロジェクトのフォルダがあります
■注意点
MeCabSharpを使えるようにするまで
MeCabSharpの配布物にMeCab.dllとMeCabSharp.dllが含まれているのですが,なぜか私の環境では,うまく動きませんでした.
どううまく動かなかったかと申しますと,解析はできて文字列も返ってくるのですが,アプリケーションの終了時にMDA*11がFatalExceptionEngineErrorを吐いてしまう問題が発生しました.
色々試してうまくいかなかったので諦めかけていたんですが,配布ページに載っている方法でMeCabSharp.dllとMeCab.dllをコンパイルし直したらうまくいきました.
配布物に同梱してあるファイルでうまくいくならそれにこしたことがないですが,うまくいかなかった場合はご自身の環境で再コンパイルしてみてはいかがでしょうか.
基本的にC#からMeCabを使おうとしている時点でVisualStudioは入っているはずなので,配布ページに載っているコンパイル手順はうまくいくはずです.
どちらも,コマンドプロンプトを起動*12して,MeCabSharpのフォルダに入って配布ページに書いてあるコマンドを実行すればOKです.
この時,libmecab.dllとiconv.dllもMeCabSharpのフォルダに入れておく必要があります.
MeCabSharpを使えるようになってから
解析に使うクラスは,TaggerであってMecabではありません.version 1.1.0.0(2007/11/24追記)
この記事を書いた時のMeCabSharpは,バージョンが1.0.0.0でしたが,8/10に1.1.0.0にバージョンアップしてMeCab0.96に対応したようです.このバージョンでは,少なくともWindowsVista/x86環境では再コンパイルが必要ありませんでした.
ただ,以前から使っている方はMeCab(libmecab.dll)のバージョンも0.96に上げた方がいいでしょう.
気になったこと
2007-11-16 - へっぽこSE m-tanakaの日記この記事によると,
ループの中でTagger.parse()を繰り返し呼ぶとMeCabがエラーで落ちてしまった。とのことですが,私の環境では出ませんでした.何でだろう…….
(とりあえず、毎回Taggerのインスタンスを生成することで回避できた)
テストに使ったコード
Tagger myTagger = new Tagger();
for (int lci = 0; lci < 5; lci++)
{
string test = myTagger.parse("何か入力文");
}
*11 : Managed Debugging Assistants
*12 : Windows XPなら【スタート→ファイル名を指定して実行→cmd】,Windows Vistaなら【左下のWindowsマーク→検索の開始→cmd】
- TB-URL http://mitc.s279.xrea.com/diary/044/tb/
-
▼
[.Net]C#のコードで動的にクラスをコンパイルして使用する
へっぽこSE m-tanakaの日記コードの実行中に、ソースコードをランタイムで動的にコンパイルして実行する方法。 using Microsoft.CSharp; using System.CodeDom.Compiler; using System; using System.Colle...
▼ 用語をメモしてみた
メモです.
間違いはコメントやメールなどで指摘して頂けると非常に嬉しいです.
間違いはコメントやメールなどで指摘して頂けると非常に嬉しいです.
■ 形態素解析器
詳細は,Wikipediaを参照して頂くとして,とりあえずこれによって普通の文章を機械で処理しやすいレベルでバラバラにできます.例えば,文章の中で一番沢山使われている単語は何かを計算するプログラムを考えて下さい.
英文が対象なら,動詞の活用などを考慮しない*1形なら,簡単にできますよね.
つまり,英文は単語と単語がスペースで区切られているので,「 」で文を分割して順番に見て行き出現した単語をカウントしていけばいいわけです.
しかし,日本語の文章ならどうでしょう.一体どこからどこまでが一つの単語かは全然わかりません.
さらに,英語の文章を対象にするにしても,活用が異なっても同じ基本形の単語はまとめてカウントしたくなることもあるでしょうし,形容詞だけを取ってきたいこともあるかもしれません.
このような場合,文章を対象にしたプログラムでは,文章を意味のある*2単位で分割し,その単位がどのような属性*3を持っているかを判別する方法があれば解決します.
そして,それをするのがまさに形態素解析器なのです.
■ TF/IDF法
参考URL- TF-IDF を改めて調査中 - Ceekz Logs
TF(Term Frequency)
索引語頻度とも呼ばれるらしいです.tf(i,j) = log2(freq(i,j) + 1) / log2(NoT)文書jにおける単語iのTF値tf(i,j)は,
文書jにおける単語iの出現回数freq(i,j) + 1のlog2を取った値を
文書jにおける単語のバリエーション数のlog2を取った値で割ったもの
(追記)
この辺実は研究によってマチマチで,logをまったくかけなかったり全体にかけていたり底も色々.
とりあえずlog無し+1も無しが基本形で,そこから適用対象によって色々調整したらいい的な感じかな?
- 1しているのは,出現回数が0だった場合対策?
「ある文書におけるある単語の出現回数をその文書中に出現する単語のバリエーション数で割ったもの」が基本.
参考
tfi = ni / Σk nk単語iのtf値は,単語iの出現回数niを文書kに出現する総単語種別で割る
参考
IDF(inverse document frequency)
逆出現頻度と訳されたりするある単語のidf値 = 全文書 / ある単語が出現する文書数参考
■ ベクトル空間モデル(Vector Space Model)
■ コサイン距離(Cosine Distance)
(コサインとサインの扱いを間違っていたので修正)ベクトル空間モデルでベクトル同士の距離を比較するための尺度.
ベクトルa(Va)とベクトルb(Vb)の距離は次式
Va = (a1,a2,a3,...,ax) Vb = (b1,b2,b3,...,bx) CosDist(Va,Vb) = 1 - ( (Va*Vb) / ( √(Va^2) * √(Vb^2) ) )1を引いている点に注意.
ベクトルの内積の求め方は次式.
Va * Vb = (a1 * b1) + (a2 * b2) + ... + (ax * bx) Va^2 = (a1 * a1) + (a2 * a2) + ... + (ax * ax)
1を引く意味
コサインは,0~1の実数を取り,値が大きいほど*4角度が0に近くなる.角度が0度の時に二つのベクトルは完全に重なるわけで,それが最も近い状態.
逆に,値が小さくなるほど*5角度が90度に近くなる.
角度が90度の時に二つのベクトルは直行するわけで,それが最も遠い状態.
しかし,コサイン「距離」を求めたいのだから値が大きい時に遠く小さい時に近くないとおかしい*6.
そのため,1を引いている.
と解釈しましたが,あっているのかわかりません.
正しい解釈や,そのソースを持っている方がいらっしゃいましたら教えて頂けないでしょうか.
参考
■ N-Gram
文書から単語群を抽出するに形態素解析を行わずに文書の頭から順にN文字ずつ切り出していく方法.N-GramのNの部分には何文字ずつ切り出すかが入る.
例えば,3-Gramで上の文を切り分けると次のようになる.
文書か……?
ら単語
群を抽
出する
に形態
素解析
を行わ
ずに文
書の頭
から順
にN文
字ずつ
切り出
してい
く方法.
なんか重複して一文字ずつズラしていく
なんかこんな形が正式なの?かな?
んか重
か重複
重複し
複して
検索エンジンの仕組み::Ngram(N-gram)とは何か & 形態素解析との比較
全文検索 - Wikipedia
- TB-URL http://mitc.s279.xrea.com/diary/045/tb/

1: ( ・(ェ)・ ) 2007年07月19日(木) 午後6時22分
工藤さんが個人的に作ったんでわ?
NTTコミュも支援したのかしら
2: miff 2007年07月20日(金) 午後0時14分
すいません.少なくともNTTコミュニケーションは嘘でした.
「日本電信電話株式会社コミュニケーション科学基礎研究所」だから「NTT」の「コミュニケーション科学基礎研究所」になりそうです.
この部分は訂正しておきます.
誰が作ったのかということですが,公式サイトの記述によると
> 京都大学情報学研究科-日本電信電話株式会社コミュニケーション科学基礎研究所共同研究ユニットプロジェクトを通じて開発されたオープンソース形態素解析エンジン
とのことで,http://web.archive.org/web/20060902230418/http://pine.kuee.kyoto-u.ac.jp/KU-NTT-WS-2005/のプロジェクトで作られたと理解しました.
ただ,詳しいことは知りません.実際はその方が個人的に作られたのでしょうか.
3: (*´(ェ)`) 2007年07月25日(水) 午後6時02分
どうなんでしょう。私も知りません。
中心的なメンバー、という感じなのかな?